利用Kubernetes提供可靠且可扩展的部署服务
AI/ML模型的自动化部署系统,支持传统数据挖掘模型和深度学习模型
部署完整的Pipelines (数据预处理 -> 模型预测 -> 预测值后处理),而不仅仅是模型本身
支持在本地私有或公有云中的Kubernetes上部署
基于Kubernetes弹性部署人工智能/机器学习(AI/ML)模型到生产环境
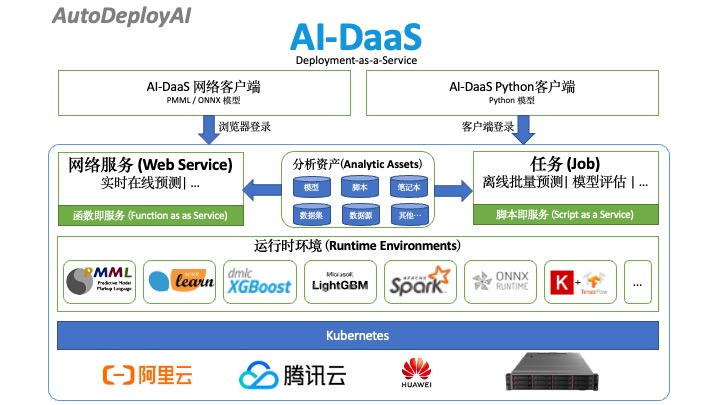
AI-DaaS
基于Kubernetes弹性部署人工智能/机器学习(AI/ML)模型到生产环境
利用Kubernetes提供可靠且可扩展的部署服务
AI/ML模型的自动化部署系统,支持传统数据挖掘模型和深度学习模型
部署完整的Pipelines (数据预处理 -> 模型预测 -> 预测值后处理),而不仅仅是模型本身
支持在本地私有或公有云中的Kubernetes上部署
产品介绍
AI-DaaS是一套基于Kubernetes的人工资能/机器学习(AI/ML)自动部署系统,提供一键式自动部署开源模型到生产环境中,支持PMML,Scikit-learn,XGBoost,LigthGBM,Spark ML和目前主流深度学习框架ONNX,TensorFlow,Keras,Pytorch,MXNet等,以及用户自定义模型的部署。
伴随开源技术的进步,数据分析师现在可以很容易的训练模型,比如在自己的电脑上安装Anaconda包,启动Jupyter notebook,使用Numpy和Pandas预处理数据,调用XGBoost或者LightGBM可以很容易的训练一个精度不错的模型。但是因为生产环境和开发环境的不同,模型的部署却不是那么容易,一些常见的问题包括:如何能同时部署数据预处理和模型本身,如何为预测推断提供REST API,如何调试REST API,如何管理模型,如何无缝切换模型版本,如何监控部署性能,如何弹性扩展部署服务,如何能批量预测并且支持不同的数据源,如何进行模型评估等等,这些问题都可以在AI-DaaS系统中找到答案。
AI-DaaS使用项目来管理用户的数据分析工作,用户可以为不同的任务创建不同的项目,在项目中可以管理各种分析资产,包括模型、部署、脚本、数据、数据源等,图一为项目首页仪表盘:
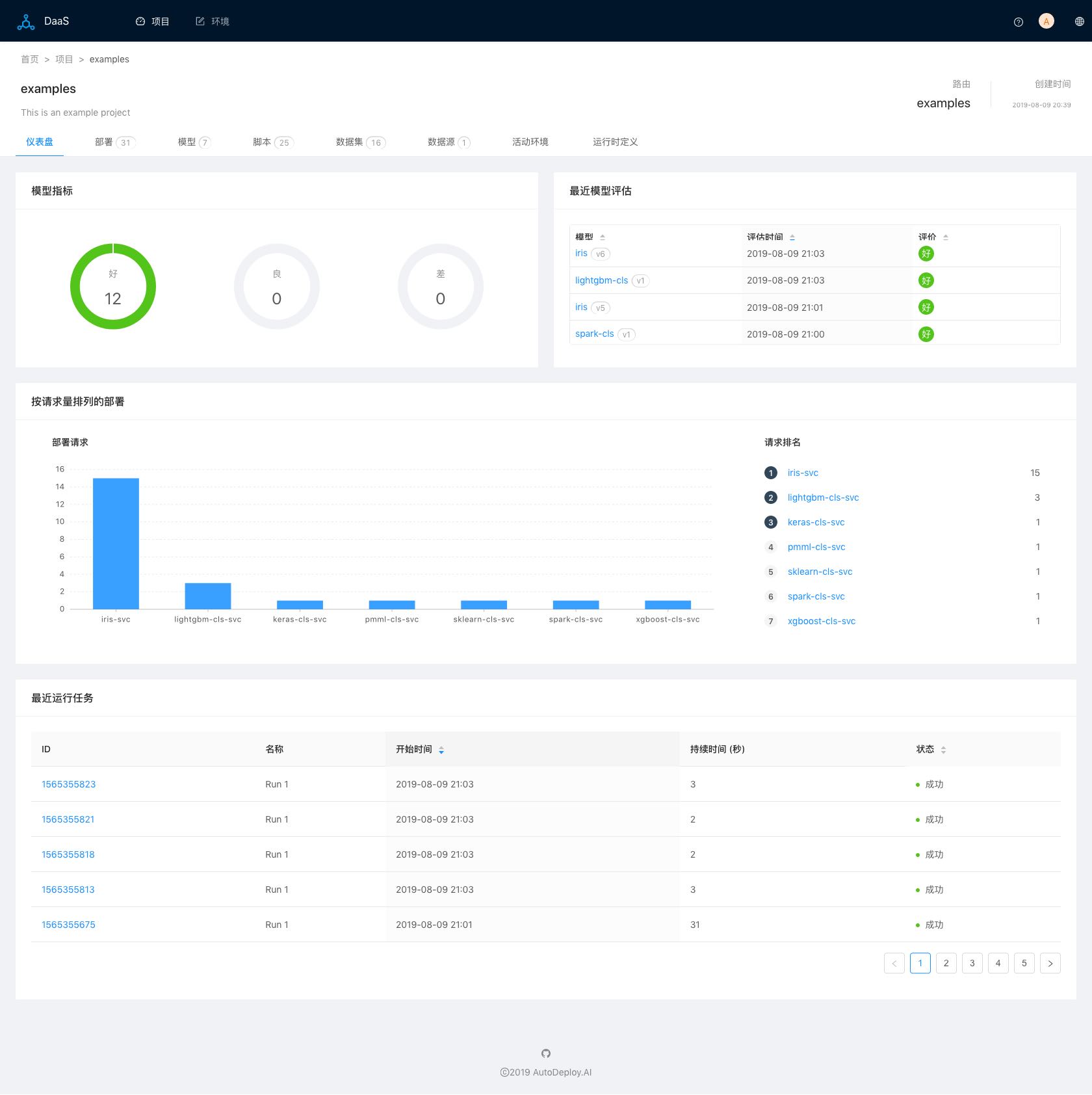
图一(项目仪表盘)
AI-DaaS支持部署Pipelines,而不仅仅是模型本身。AI-DaaS基于函数即服务(Function-as-a-Service)构建,自动为多种编程语言函数生成REST API。在AI-DaaS中,用户可以很容易创建包含了模型预测功能的程序脚本,基于该脚本,用户可以自由添加数据预处理或者预测值后处理的函数或者代码,满足用户各种自定义功能。以AI开发语言Python为例,下图二是AI-DaaS自动生成的用户自定义预测脚本:
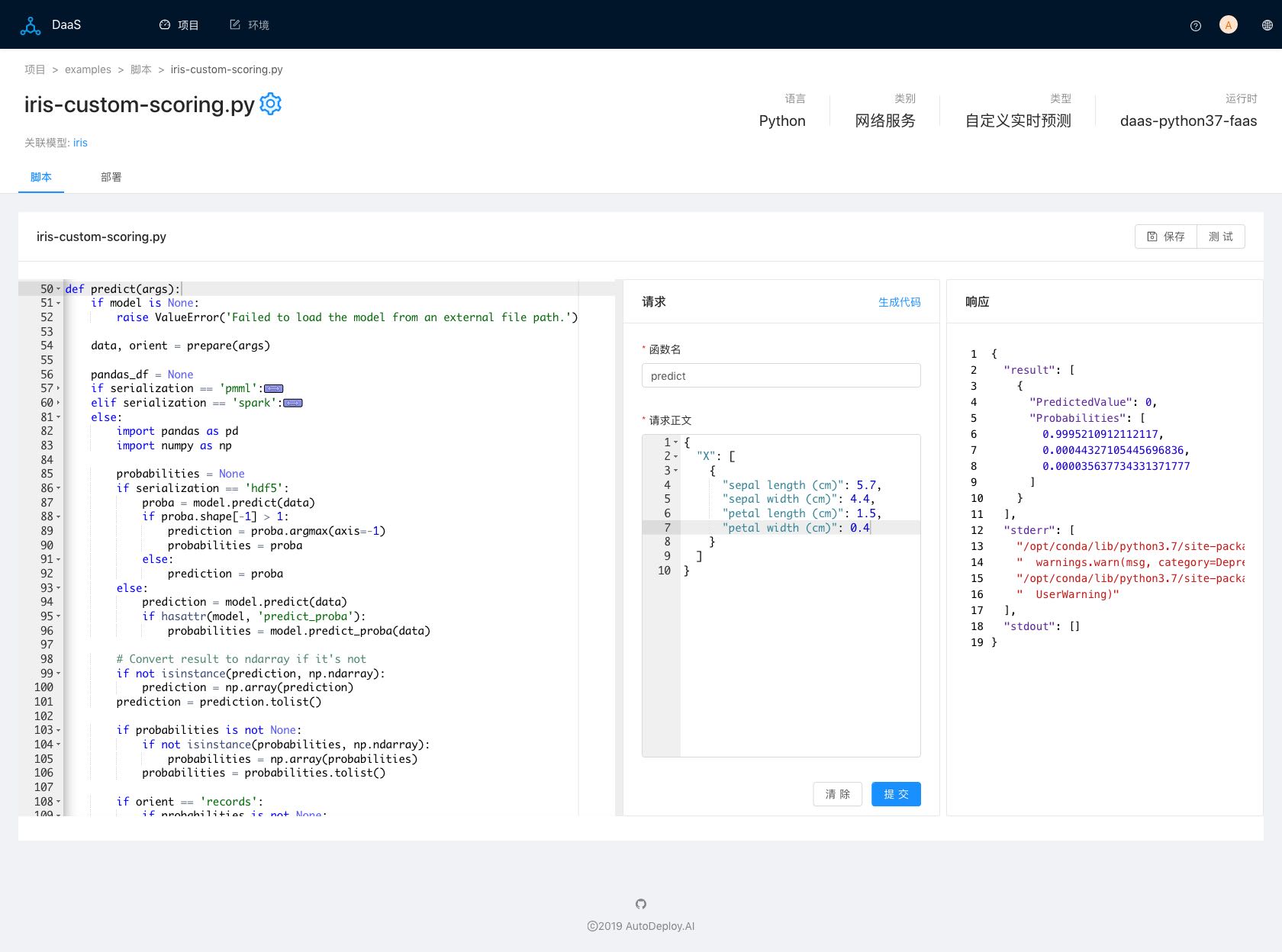
图二(自定义预测脚本)
AI-DaaS提供两套API,分别针对开发和产品模式,用户可以在图二界面中使用开发API来测试添加的功能,测试完成后,再创建正式的网络部署,上线完整的Pipelines, 或者使用任意的REST客户端来测试,关于API信息,可以点击命令“生成代码”来获取,图三所示:
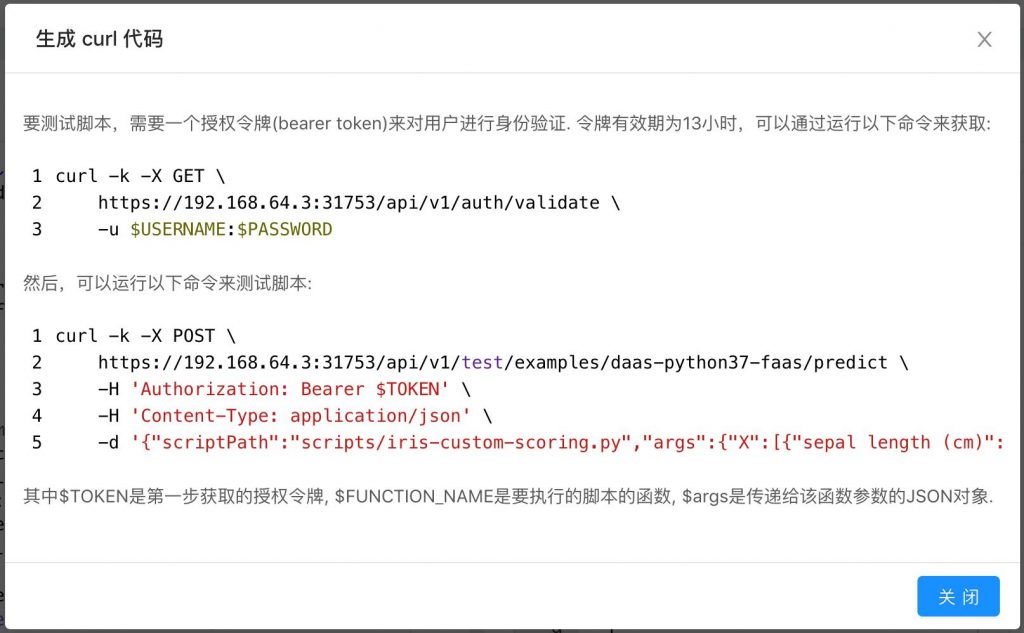
图三(测试API)
借助于AI-DaaS Web界面可以直接部署PMML和ONNX模型,或者DaaS-Client客户端(目前支持Python)部署其他基于Python主流开源模型:
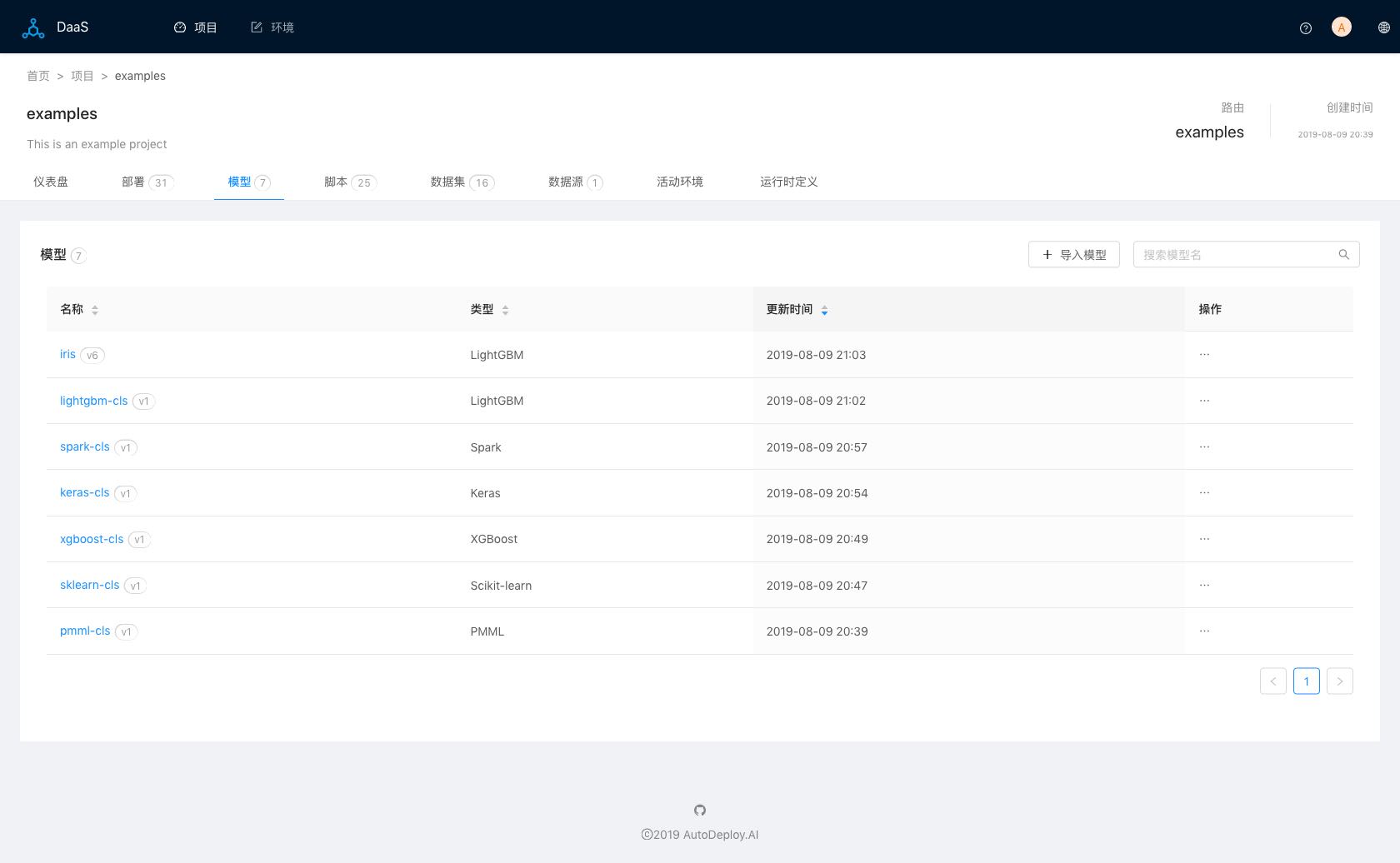
图四(模型列表)
支持添加和管理模型的不同版本:
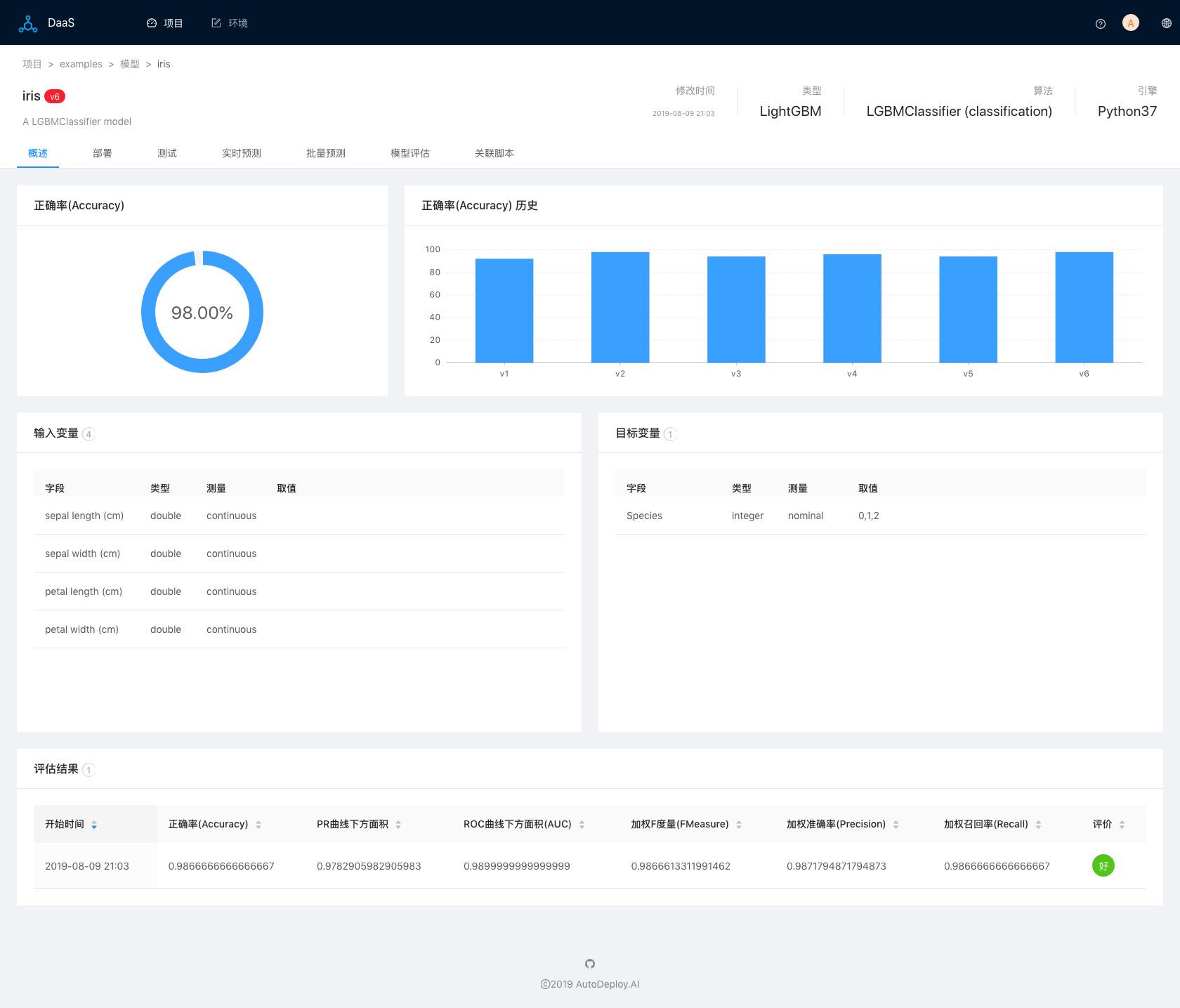
图五(模型概述))
监控部署性能,提供各种网络服务性能指标:
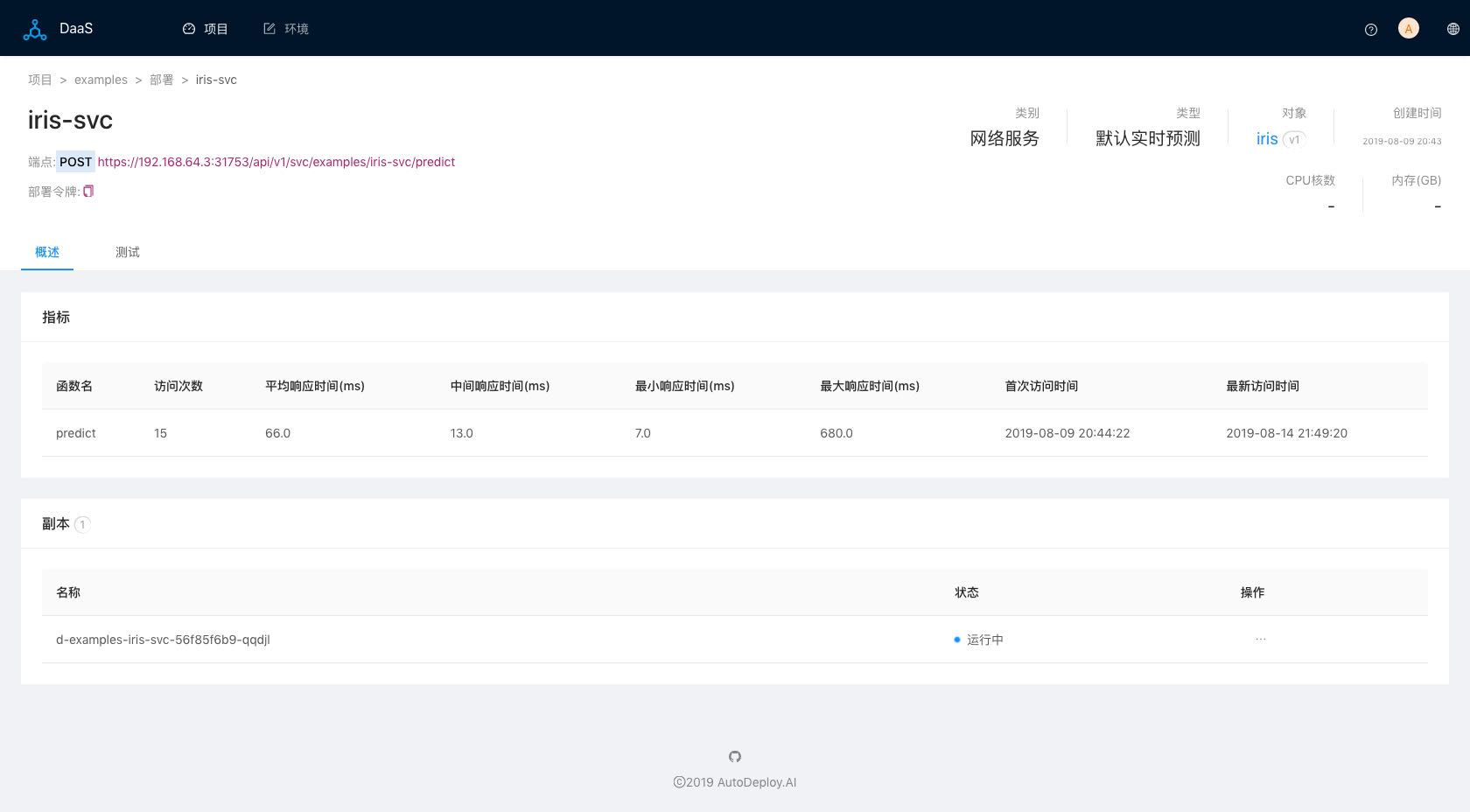
图六(网络服务部署)
支持自由切换部署的模型版本,提供网络负载,增加或者减少部署副本量,弹性扩展部署服务:
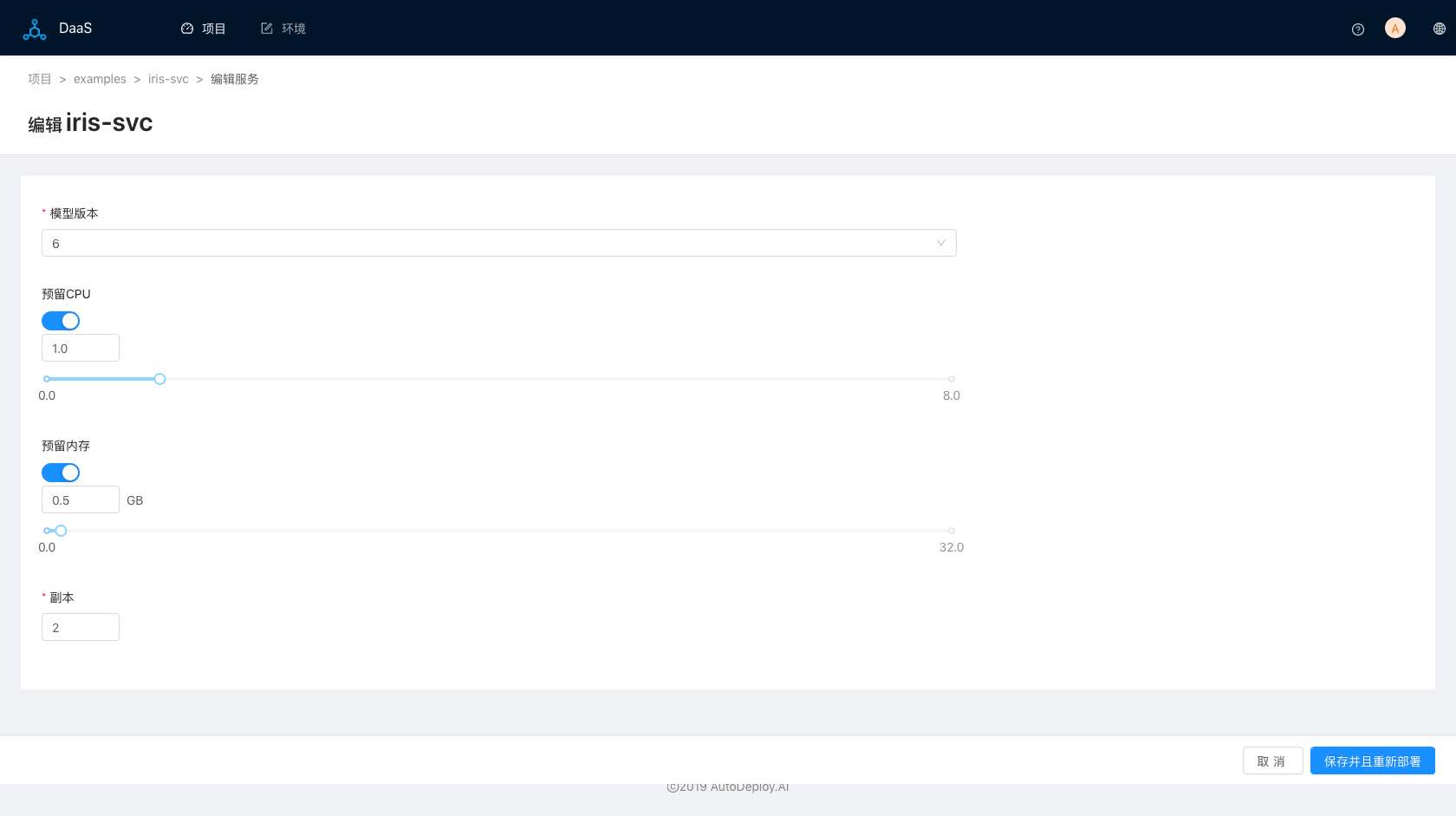
图七(更新网络服务部署)
除了支持部署网络服务,AI-DaaS还可以部署任务,用户可以在任务中执行任何自定义操作。AI-DaaS支持生成批量预测和模型评估的脚本,用户可以通过部署任务来执行:
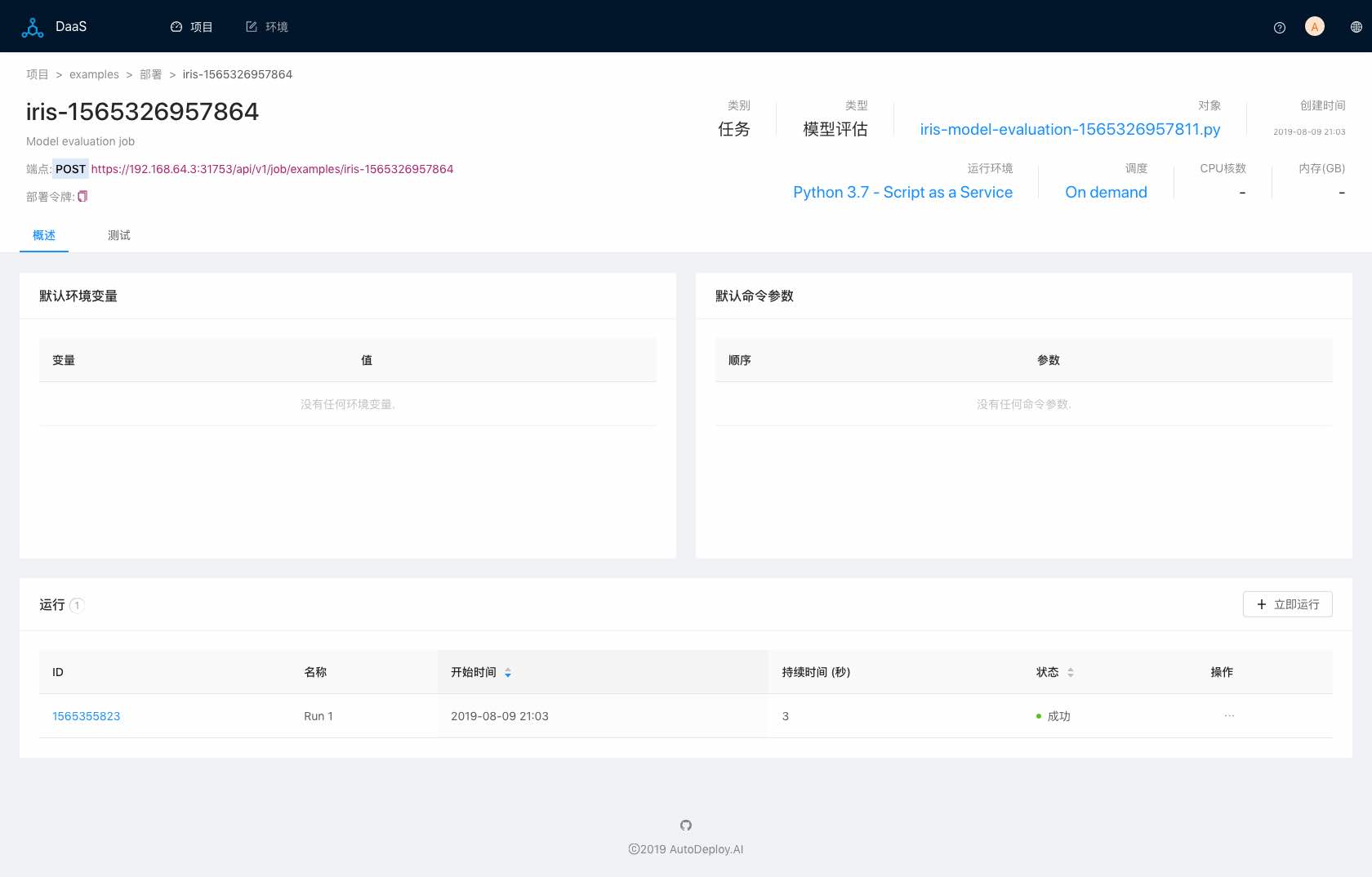
图八(任务部署)